How to manage 2 petabytes of new data every day
Extracting as much information as possible from operation will allow ITER to make the most efficient use of the machine. Some of the data will be immediately needed as input into models that help determine the state of the plasma, while virtually all of the data will be needed for rigorous analysis that will help researchers better model nuclear fusion, ultimately providing essential tools and know-how to future designers of DEMO and commercial reactors.


"By around 2035 ITER will produce 2 petabytes of data on a daily basis," says David Fernandez, Section Leader of the IT System & Operation Section. "To give you an idea how much that is, the total amount of data the ITER Project has today, including data in the different Domestic Agencies, is on the order of 2.2 petabytes. By 2035, we will be producing this volume every day."
By far the biggest generators of raw data at ITER will be the diagnostic systems taking at least two different kinds of measurements of all the important parameters within the reactor—these redundant measurements reduce uncertainties and increase confidence in values that cannot be measured directly and must be inferred from other measurements. The 2 petabyte projection is based on the current generation of diagnostic systems with today's camera resolutions. If the technology is upgraded in the future, data rates are likely to increase by an order of magnitude.
ITER already has several clusters to perform computation jobs in domains such as neutronics, physics modelling, simulations and analysis. Taken together, these clusters currently consist of about 7,000 processing cores. In addition to compute capacity, ITER has the storage capacity to handle current needs. But to meet future requirements, both compute and storage need to be ramped up.

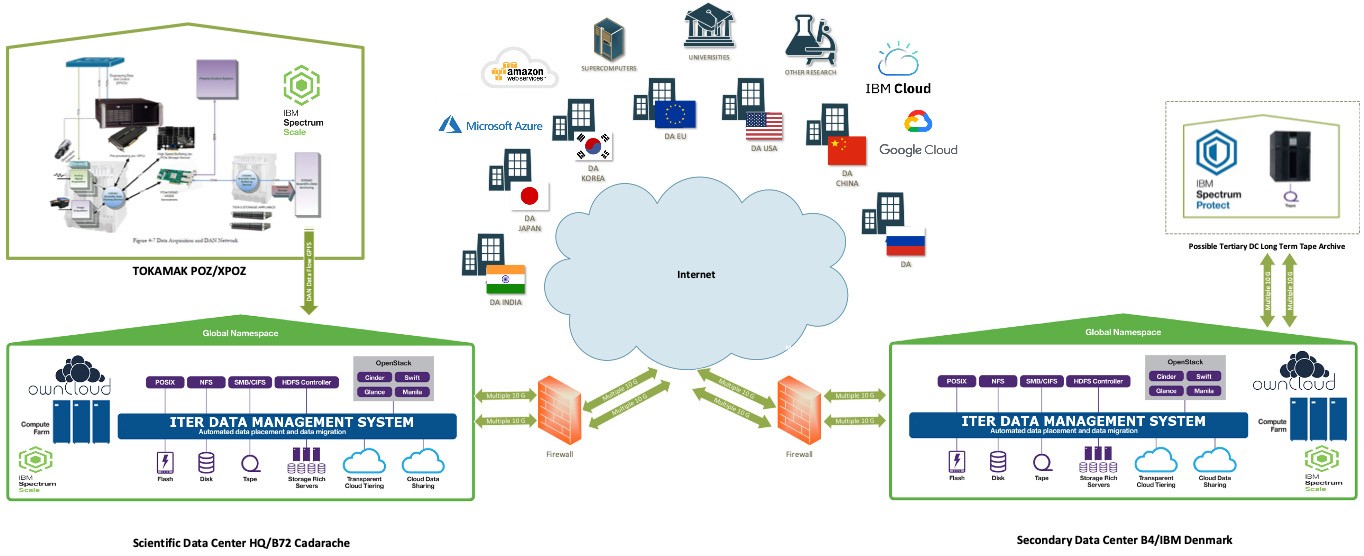
Developing the capacity to store, secure and replicate a tsunami of data
To meet those future needs, in 2019, the head of the Science, Controls & Operation Department, Tim Luce, and the head of the Information Technology Division, Jörg Klora, developed plans for a new Scientific Data and Computing Centre. These plans were endorsed in early 2020.
"The physical data centre should be finished around 2023, ready for integrated commissioning which will commence in 2024," says Peter Kroul, Computing Center Officer of the IT System & Operation Section. "We have already begun to bring the different systems online, in the existing data centres, and will move them to the new Scientific Data and Computing Centre when it's finished. No later than mid-2024, everything has to be operational, ready for the diagnostic systems that will all be installed by 2024 and run through 2025 in preparation for First Plasma."
The first iteration of the Scientific Data and Computing Centre will be around 250 m² on two levels in the ITER Headquarters building. It will contain 48 high-density racks. "This is really squeezing and optimizing everything to the extreme," says Kroul. "If we extrapolate from the evolution of technology over the past 20 years, and project the same rate of improvement into the future, that amount of physical space will be enough until 2032. Of course that assumes we always use the latest storage technology and that we continue to optimize our use of the space. After 2032 we may need more room. That will all depend on the evolution of storage technology available on the market."
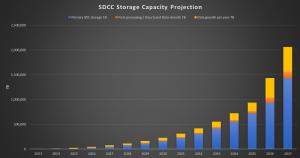
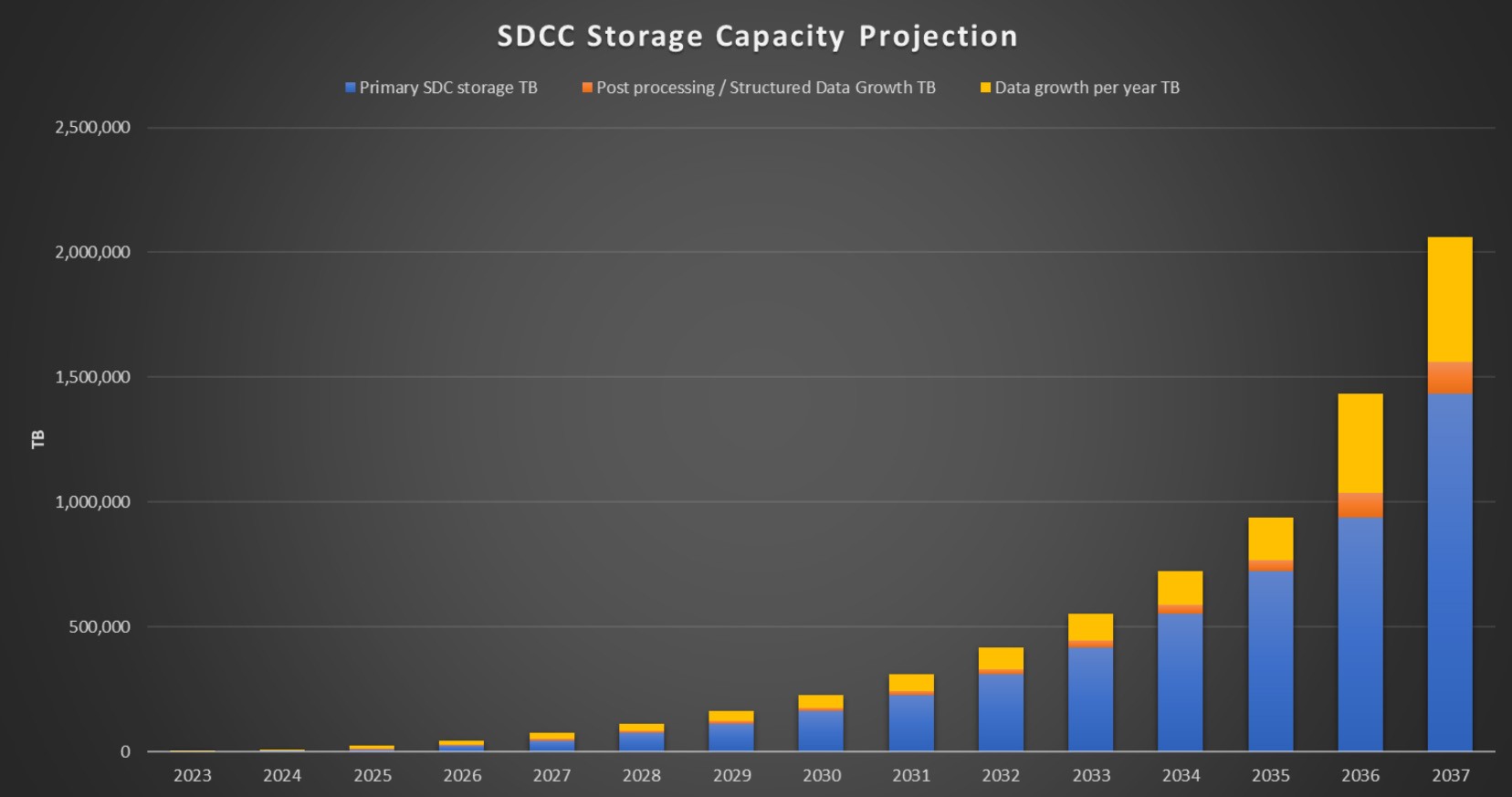
The need for storage space will increase very quickly once operations begin and 2 petabytes of new data are generated every day. By 2035, the new data centre will have to hold nearly 1 exabyte of data. Two years after that, in 2037, the storage requirements will have surpassed 2 exabytes. (See graph.)
As for computational power, Simon Pinches, Section Leader of the Plasma Modelling & Analysis Section, says ITER will not need a super computer: "General-purpose-computing clusters will meet our on-site needs for processing the data to do preliminary research. The incredibly in-depth analysis—examining each time slice and really going down to the simulations of the different turbulent eddies within the plasma—will take place within the different ITER Member institutes that do have access to supercomputers."
"We will also complement our on premises infrastructure with storage capacity and computational power in public clouds and in other data centres," says Fernandez. "The plan is to only have the necessary computing power in the data centre itself."
At least one copy of the raw data will be kept centrally at ITER along with at least one backup copy at a redundant data centre 50 kilometres or more from ITER. Replicating 2 petabytes every day is itself a feat, requiring tremendous network capacity for secure transfer.
Sharing data with Members
To help researchers prepare tools for analysis, special care is being taken to establish data norms early. "Currently the data generated by different fusion reactors is represented in different ways," says Pinches. "We've come up with a common representation for data that can be used across all machines in a way that enables ITER Members to start preparing for ITER operations."
"We've developed the Integrated Modelling and Analysis Suite (IMAS), which is built around a common data dictionary that can be used for all machines, including ITER," says Pinches. "We've declared it in advance—and now the ITER Members are helping us refine it, extend it, use it and test it. It allows everybody to help prepare well in advance before we have any ITER diagnostic data. This also allows us to start testing analysis tools early, using their data in the representation we've defined."
In some cases, ITER will provide remote access to information. "Many of the people will be supporting experiments offsite and will need to follow the data," says Pinches. "So we have to provide a system that can allow people to view these potentially large amounts of data, even if they're remote."
"While we will do first stage processing and analysis immediately following an experiment, there will be much more detailed analysis done by other people all over the world. They will be able to remotely connect and see the data and interact with it. A lot of this will be done through a remote screen at ITER. They will also be able to fetch data and work on it locally at their machines. The networks will have to support a very high volume of data."