Comment gérer chaque jour deux pétaoctets de nouvelles données ?
Pour optimiser l'usage de la machine, ITER devra extraire le plus grand nombre d'informations possible de son retour d'expérience. Certaines de ces informations constitueront les données d'entrée des modèles utilisés pour déterminer l'état du plasma, tandis que la plus grande partie devra être finement analysée pour permettre aux chercheurs de mieux modéliser la fusion nucléaire, et d'élaborer ainsi les outils et le savoir-faire essentiels aux concepteurs de DEMO et des futurs réacteurs commerciaux.


« Vers 2035, ITER produira quotidiennement deux pétaoctets de données, indique David Fernandez, chef de la Section système et opérations informatiques. Pour vous donner une idée de ce que cela représente, le volume total de données dont dispose aujourd'hui le programme ITER, y compris celui qui a été généré par les différentes agences domestiques, est de l'ordre de 2,2 pétaoctets. D'ici 2035, c'est le volume que nous produirons chaque jour. »
En réalisant au moins deux types de mesures de chacun des paramètres-clé du réacteur, les systèmes de diagnostic seront de loin les plus grands producteurs de données brutes. Ces mesures redondantes visent à réduire les marges d'incertitudes et à renforcer la confiance dans les valeurs qui, ne pouvant être mesurées directement, doivent être extrapolées d'autres mesures. Cette projection de deux pétaoctets se fonde sur la production présente des systèmes de diagnostic, obtenue avec la résolution dont disposent aujourd'hui les instruments d'observation. Si la technologie et la résolution progressent, le débit des données devrait augmenter d'un ordre de grandeur.
ITER dispose déjà de plusieurs clusters pour effectuer les calculs dans des domaines tels que la neutronique ou les modélisations, simulations et analyses physiques. Ensemble, ces clusters comptent aujourd'hui près de 7 000 processeurs. Outre cette puissance de calcul, ITER dispose d'une capacité de stockage qui répond aux besoins actuels. Mais pour satisfaire aux exigences futures, ces deux capacités devront être accrues.

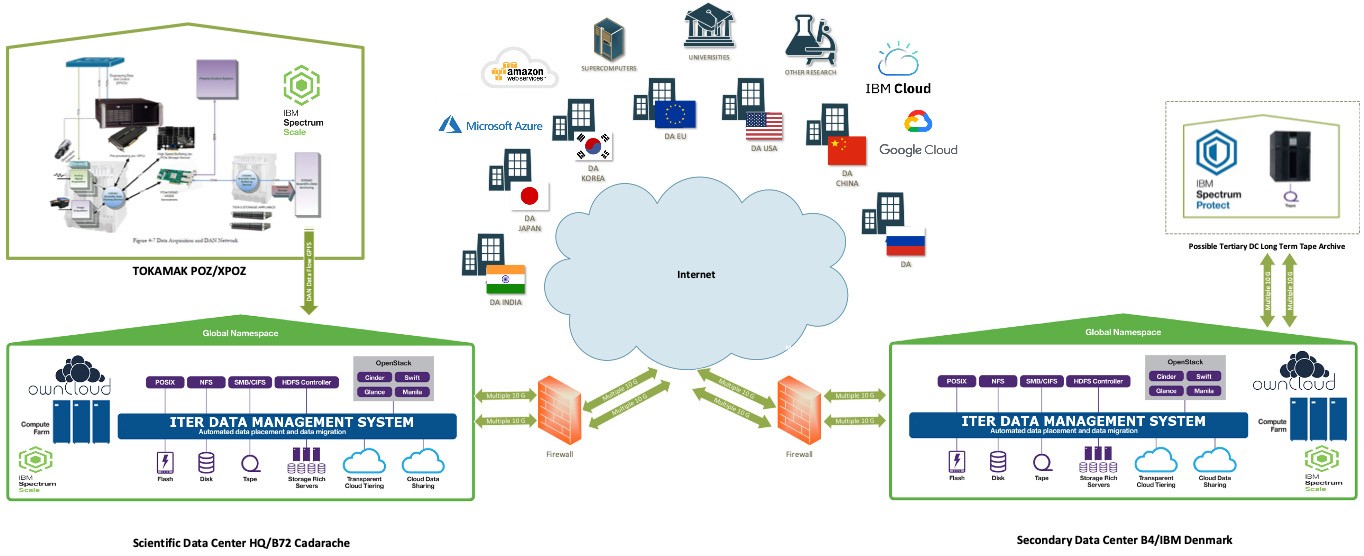
Développer la capacité de stockage ; sécuriser et dupliquer une avalanche de données
Pour répondre aux besoins à venir, Tim Luce, le directeur du Département science, contrôles et opérations, et Jorg Klora, le directeur de la Division des technologies informatiques, ont élaboré en 2019 les plans d'un nouveau Centre de calcul et de données scientifiques. Ces plans ont été validés au début de l'année 2020.
« Le centre de données physiques devrait être terminé vers 2023, prêt pour une mise en service intégrée à partir de 2024, précise Peter Kroul, du Centre de calcul de la section Systèmes et opérations informatiques. Nous avons déjà commencé à mettre en place les différents systèmes dans les centres de données existants en attendant de les transférer dans le nouveau Centre de calcul et de données scientifiques lorsque celui-ci sera terminé. Tout devra être opérationnel au plus tard courant 2024 pour accueillir les systèmes de diagnostic qui seront installés avant 2024 et mis en service en 2025 en prévision du premier plasma. »
La version initiale du Centre de calcul et de données scientifiques occupera environ 250 m² sur deux niveaux dans le bâtiment du siège d'ITER. Il abritera 48 baies de haute densité. « Tout est concentré et optimisé à l'extrême, note Peter Kroul. Si l'on se base sur l'évolution technologique de ces vingt dernières années, nous pensons qu'avec un taux d'amélioration similaire dans le futur ce volume physique devrait être suffisant jusqu'en 2032. Bien entendu, cela suppose que nous adoptions toujours la technologie de stockage la plus récente et que nous continuions à optimiser notre utilisation de l'espace. Au-delà de 2032, nous pourrions avoir besoin de plus de place. Cela dépendra de l'évolution des technologies de stockage disponibles sur le marché. »
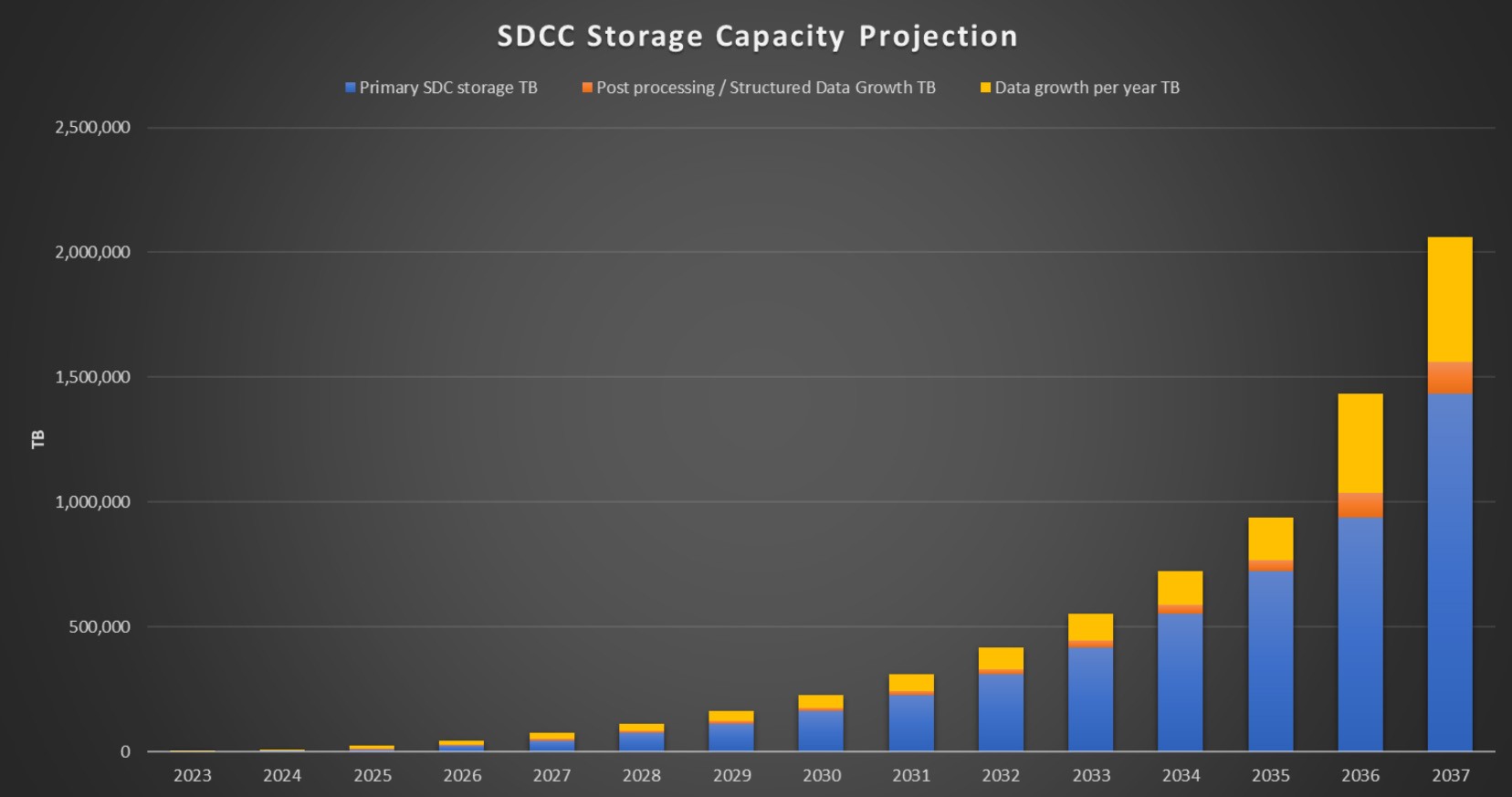
Le besoin d'espace de stockage augmentera très rapidement après le lancement de l'exploitation, et deux pétaoctets de nouvelles données seront générés chaque jour. D'ici 2035, le nouveau centre de données devra héberger près d'un exaoctet de données. Deux ans plus tard, en 2037, les besoins de stockage dépasseront deux exaoctets (voir graphique).
« Nous ajouterons également à nos infrastructures locales une capacité de stockage et une puissance de calcul issue des clouds publics et d'autres centres de données, précise David Fernandez. L'objectif est de n'avoir que la puissance de calcul nécessaire dans le centre de données lui-même. »
Au moins une copie des données brutes sera sauvegardée localement, tandis qu'au moins une copie de sauvegarde le sera dans un centre de données redondant, situé à une distance minimale de 50 kilomètres du site. Dupliquer chaque jour deux pétaoctets est en soi un exploit, qui exige une capacité réseau exceptionnelle pour assurer la sécurité des transferts.
Partager les données avec les membres
Pour faciliter la préparation des outils d'analyse, on s'est attaché à définir en amont les normes de présentation des données. « Aujourd'hui, les données générées par différents réacteurs de fusion sont présentées de différentes manières, explique Simon Pinches. Nous sommes parvenus à une présentation commune des données, qui peut être utilisée sur l'ensemble des machines de manière à permettre aux membres du programme d'entamer la préparation des opérations ITER. »
« Nous avons développé l'outil IMAS (Integrated Modelling and Analysis Suite), précise-t-il. Il est construit autour d'un dictionnaire de données utilisable sur toutes les machines, y compris ITER. Nous l'avons communiqué aux membres d'ITER qui nous aident maintenant à le perfectionner, à le compléter, à l'utiliser et à le tester. IMAS permet à chacun de se préparer bien avant que nous disposions de données de diagnostic d'ITER. Cela nous permet également de commencer sans délai à tester les outils d'analyse en utilisant leurs données dans la représentation que nous avons définie. »
Dans certains cas, ITER fournira un accès à distance aux informations. « De nombreuses personnes contribueront aux expériences sans être présentes sur site et devront pouvoir accéder aux données, précise Pinches. Nous devons donc fournir un système leur permettant de visualiser à distance ces volumes de données potentiellement importants. »
« Tandis que nous procèderons à la première étape de traitement et d'analyse immédiatement après une expérience, d'autres personnes, dans le monde entier, effectueront des analyses nettement plus détaillées. Elles pourront se connecter à distance, examiner les données et interagir avec elles. Cela passera en grande partie par l'intermédiaire d'un écran installé dans les locaux d'ITER. Ces personnes seront également en mesure de récupérer des données et de les traiter localement, avec leurs propres machines. Les réseaux devront prendre en charge un volume très important de données. »